This is the first in what will likely be a series of blog posts about Clean Architecture. Uncle Bob Martin has written numerous blog posts and given lots of talks about it.
The goal of Clean Architecture is to have the directory structure of your application shout out what your application does rather than what framework was used to present your application or what database is nestled in the depths of your application. Your program is divided into Entities, Use Cases, and Interface Adapters.
Entities encapsulate “Enterprise-wide business rules.” Use Cases encapsulate “Application-specific business rules.” Interfaces and Adapters represent how your Use Cases want to interact with the outside world (e.g. databases, users, printers, etc.).
In Clean Architecture, the Entities cannot know that the Use Cases exist and the Use Cases cannot know anything about the Adapters except for the Interface to them which is defined by the Use Case rather than by the Adapter. The Use Case does not know whether the application is being used from the command-line or from the web or from a remote service calling into it. The Use Case does not know whether the data is being stored in the file system or in a relational database (or conjured from the ether as needed). Nothing in the Adapters can know anything about the Entities.
Simple Example
I have a project that I am just starting. I thought I would use this new project to see how Clean Architecture works for me.
There are large number of talks and videos about Clean Architecture. However, there are not many examples of it despite several years of Stack Overflow questions and blog posts asking for examples.
There are a few simple examples around the web. The most notable is Mark Paluch’s Clean Architecture Example. It is just big enough to get a sense of how things hang together. If you’re willing to put up with Java’s insane directory hierarchies, you can get a pretty good idea of what the application does just by poking around the Use Cases directory.
My First Use Case
My first Use Case is to let the User browse a list of Book Summaries. The User should be able to sort by Title, Author, Publication Date, or Date the Book was acquired. The User should be able to filter the list based upon Genre or Keyword. The Use Case should allow the caller to implement pagination, so the Use Case needs to support returning up to a given number of Book Summaries starting with a specific number.
Some might argue that that is multiple Use Cases glommed together. If that were the case, then I would need some way to pipeline together Use Cases if I’m going to make any sort of reasonably navigable app atop my Use Cases.
But, let’s start with baby steps.
The Simplified Version of my First Use Case
Let’s just say the User wishes to see a list of all of the Book Summaries. The User is fine with seeing all of them at once in whatever order my app sees fit.
This simple version of the Use Case is implemented in an accompanying repository under the tag the-dream.
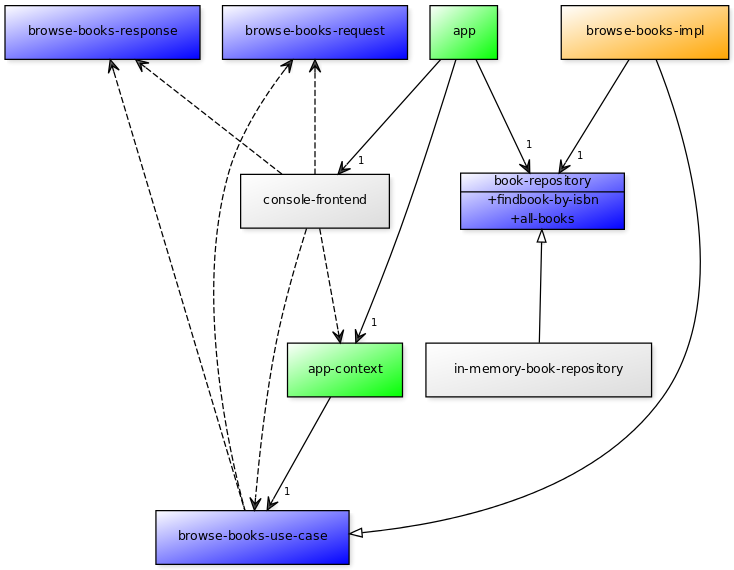
The architecture consists of some simple structures with no “business logic” in them at all: book-summary and book.
isbn
title
author
cover-page-thumbnail)
(defstruct book
isbn
title
author
cover-page-thumbnail
cover-page-fullsize
list-of-thumbnails
table-of-contents
synopsis
publication-date
list-of-genres
list-of-keywords)
There is one use case browse-books which defines the use-case interface browse-books-use-case along with its input structure browse-books-request and its output structure browse-books-response. The use case defines the method browse-books which must be called with a browse-books-use-case instance, a browse-books-request instance, and browse-books-response instance.
(defstruct browse-books-response
list-of-book-summaries)
(defclass browse-books-use-case ()
())
(defgeneric browse-books (use-case request response))
In my implementation, the browse-books-response is a simple data structure. One could easily imagine that the browse-books method would return one rather than filling one in that was passed to it. In some variants of Clean Architecture (like the Paluch example cited above), the response model is a class instance upon which a method is called to complete the interaction. But, it would have to be clear from the outset that anyone using this Use Case cannot depend on it being synchronous or asynchronous.
The use case also defines the book-repository interface that it needs.
())
(defgeneric find-book-by-isbn (book-repository isbn))
(defgeneric all-books (book-repository))
In the Paluch example, all of the use cases share the same repository interfaces (though Paluch and others have separate repository interfaces for Users and Invoices and Items). In several of Uncle Bob’s videos, he makes the claim (or claims equivalent to the claim) that each use case should define an interface for just the methods it needs to use on a Book repository. In this use case, it would need only the ability to retrieve the list of Books and so I should not have defined find-book-by-isbn here at all, and I should have named this interface browse-books-book-repository.
I wrote browse-books-impl class which extends the browse-book-use-case. It takes an instance of book-repository on construction.
((book-repository :initarg :book-repository :reader book-repository)))
(defun make-browse-books-use-case (book-repository)
(check-type book-repository book-repository)
(make-instance 'browse-books-impl :book-repository book-repository))
It uses that to retrieve the list of Books. Then, it creates a book-summary from each book instance retrieved from the book-repository.
(check-type book book)
(make-book-summary :isbn (book-isbn book)
:title (book-title book)
:author (book-author book)
:cover-page-thumbnail (book-cover-page-thumbnail book)))
(defmethod browse-books ((use-case browse-books-impl)
(request browse-books-request)
(response browse-books-response))
(let* ((books (all-books (book-repository use-case)))
(summaries (mapcar #'summarize-book books)))
(setf (browse-books-response-list-of-book-summaries response) summaries))
response)
To test the design so far, I wrote in-memory-book-repository backend which implements the book-repository interface that was defined in the Use Case.
((books :initarg :books :reader books)))
(defun make-in-memory-book-repository (books)
(check-type books list)
(assert (every #'book-p books))
(make-instance 'in-memory-book-repository :books books))
(defmethod all-books ((book-repository in-memory-book-repository))
(mapcar #'copy-book (books book-repository)))
I also wrote a console frontend which invokes the browse-books-use-case.
(let ((request (make-browse-books-request))
(response (make-browse-books-response)))
(browse-books *browse-books-use-case* request response)
(mapcar #'console-print-summary
(browse-books-response-list-of-book-summaries response))
(values)))
...
(defun console-main-loop ()
(catch 'console-quit
(with-standard-io-syntax
(loop
:do (mapc #'console-print
(multiple-value-list
(console-eval (console-read))))))))
To tie it all together, I wrote app-context which holds the current browse-books instance.
And, I wrote the app which creates an instance of the in-memory-book-repository and creates the browse-books-impl for the app-context. Then, it runs the main loop of the console frontend.
(let* ((book-repo (make-in-memory-book-repository books))
(*browse-books-use-case* (make-browse-books-use-case book-repo)))
(console-main-loop)))
Trouble In Paradise
Already, in this simple interface, I am torn. For this Use Case, I do not need the repository to return me the list of Books. I could, instead, ask the repository to return me the list of Book Summaries. If I do that, my application is just a fig-leaf over the repository.
Well, the argument against asking the repository for Book Summaries is that it should not be up to the database to decide how I would like to have my Books summarized. That certainly seems like it should be “business logic” and probably “application specific” business logic at that.
So, fine. I will have the repository return Books and the Use Case will summarize them.
Now, let me extend the Use Case the next little bit forward. What if I want to support pagination? My choices are to push the pagination down to the repository so that I can ask it to give me up to 20 Books starting with the 40th Book. Or, I can let the repository give me all of the books and do the pagination in the Use Case.
start max-results)
Here, I can find no guidance in any of the Clean Architecture videos that I have watched nor in the examples that I have found online. Everyone seems happy with the repositories being able to return one item given that item’s unique identifier or return all of the items.
If the repository is going to return all of the Books, then why wouldn’t my Use Case just return them all and leave the caller to do any pagination that is needed?
This works fine when there are a few dozen books and they are small. It does not scale, and I don’t know how it is supposed to scale without pushing most of the responsibility onto the repository.
Sure, I can push the responsibility onto the repository. But, one of the reasons that Clean Architecture is so structured is to allow easy testing of all of the application logic. The more that I push into the repository, the less that I actually exercise when I run my unit tests with my mock repository (and the more complex my mock repository should probably be).
One possible approach would be to have the all-books method instead be all-isbns. Then, I can retrieve all of the ISBNs and use find-book-by-isbn to get all of the books.
Now, if I want to sort by Author then by Title, I need to:
- fetch all of the ISBNs
all-isbns, - fetch each ISBN’s title,
- sort my ISBNs by title,
- fetch each ISBN’s author,
- stable-sort my ISBNs by author,
- clip to my range,
- fetch each book in my range,
- summarize each fetched book
Or, I have to write an SQL query, that can do all of that in one database call instead of 2N + R + 1 calls (where N is the number of books in the database and R is the number of books in my range), making my Use Case a fig-leaf again.