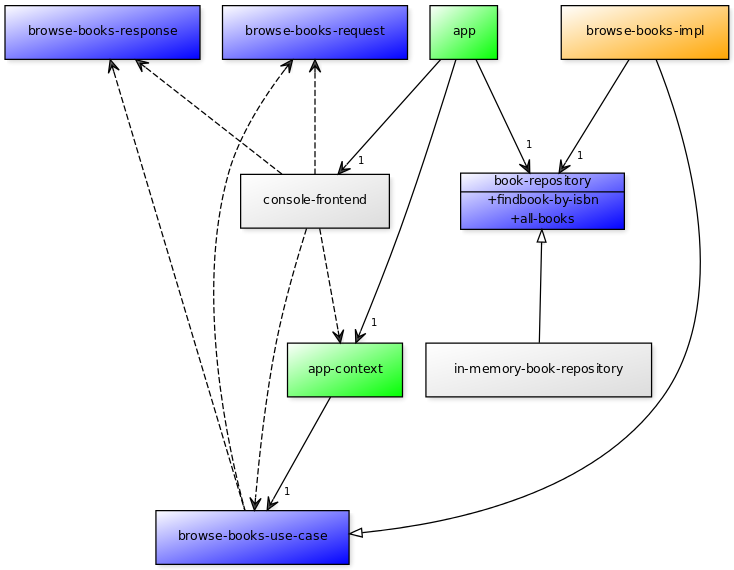
In response to my previous article, Holger Schauer asked why I implemented the use-cases with classes rather than having the book repository passed into the browse-books method or putting it into the abstract base-class browse-books-use-case rather than in the implementation.
book-repository)
(defgeneric browse-books (request response))
;; -- or --
(defgeneric browse-books (book-repository request response)
;; -- or --
(defclass browse-books-use-case ()
((book-repository :initarg :book-repository :reader book-repository)))
I started to reply, but I found that I was having trouble keeping my response to a reasonable length. So, here, you are subjected to my unreasonably long response.
For reference, here is the repository from the previous post.
Java’s Influence
I chose to model the use-cases as classes to be faithful to all of the implementations that I’ve seen of Clean Architecture. Uncle Bob, in particular, does most of his videos and talks using Java or Ruby. When he uses Ruby, he still tends to use the same OO organization that he would use if he were writing Java.
One aspect of Java is that everything has to be a method on some class. If you want to declare a method somewhere but have its implementation somewhere else, you can do this with an abstract base class or an interface. You cannot, for example, declare an abstract static method as you can in CLOS (or even C).
Java’s single-inheritance makes it very awkward in general to use abstract base classes. If the book-repository slot were on the browse-books-use-case rather than on the implementation, this would have to be an abstract base-class and direct inheritance if it were in Java. If the book-repository slot is on the implementation rather than on the browse-books-use-case, then someone writing this in Java could use an interface and an implementation of that interface.
I wrote this blog post using Lisp/CLOS. However, for the actual project that I am working on, I have opted to use PHP. PHP shares Java’s inheritance restrictions. A class can only have one superclass but it can implement any number of interfaces.
The Stated Advantages of Clean Architecture
When Uncle Bob talks about why to use Clean Architecture, he tends to focus on these things:
- Ability to defer decisions about the frontend and backend
- Ability to test the core logic of the application easily
- Ability to deploy your application in pieces
The adapters depend on interfaces defined in the application. The application does not depend on anything defined by the frontend or the backend. As such, deciding which frameworks to use on the frontend or which database to use on the backend can be deferred for a long time during the development process. Uncle Bob often describes how on FitNesse they developed using the filesystem as the database backend fully intending to plug in a relational database later in the project. In the end, they decided that the filesystem backend they had created served their purposes just fine. When they came upon a client who had requirements that all of the dynamic content be stored in their corporate database, they rewrote an adapter for that customer to use the database rather than the filesystem.
Clean Architecture applications are easy to test because the application code isn’t interwoven with the presentation code or the database code. One can create mocks (even test-specific mocks) for the repositories and front-ends that do whatever the test needs to have done. They can do it quickly, without temporary databases or network overhead.
In a Clean Architecture deployment of my application in Java, I might have one JAR file for the book repository implementation, one JAR file for the Console frontend, one JAR file for the application core logic, and one JAR file that wires all of those other pieces together on startup. If I need to incorporate a different database, then I only need to update the book repository implementation JAR and (maybe) the JAR file that wires the pieces together. I don’t have to redeploy my entire application every time the database changes. I don’t have to retest every bit of application logic. Everything is nicely contained.
An Unspoken Benefit of Clean Architecture
One of the ways that Clean Architecture keeps its dependencies in check is by making all of the interfaces going into or out of your application use primitive types or dumb structures for parameter passing. The unspoken benefit of this is that it encourages you to keep the interfaces as spartan as possible.
If the controller (the console in my sample application) that is invoking the use case doesn’t absolutely need to know there is a book repository involved, then it shouldn’t know about it. The book repository cannot be passed from the controller to the use case using primitive types and dumb structures.
The controller’s job is to take input from the user, turn it into a request, invoke the use case with that request, and present the response back to the user. There is no input that the controller can get from the user which will allow it to instantiate a book repository. It could, of course, pull it from global state as it pulled the use case. However, the less it needs to know, the better.
This separation has other benefits, as well. In Lisp, especially, one could imagine interacting with the application through the REPL. So, rather than implementing the simple REPL that I did with my console, I could have made a browse function that invokes the use-case and returns the results.
(let ((request (make-browse-books-request))
(response (make-browse-books-response)))
(browse-books *browse-books-use-case* request response)
(mapcar #'book-summary-to-plist
(browse-books-response-list-of-book-summaries response))))
If everything is going to happen within my one Lisp image, then it would be fine to keep a *book-repository* global to pass into the use case. However, if I want to share the book repository between multiple users, each at their own REPL, then it no longer makes sense that each REPL would need a handle to the book repository.
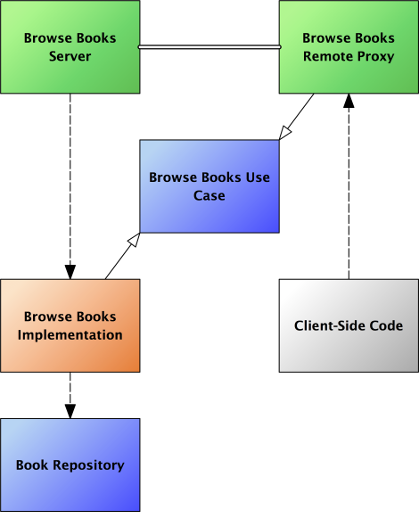
My browse function doesn’t need to know whether the use case it is interacting with is the actual implementation or just a proxy for the implementation. In the client-server case, it makes little sense for the client to have any idea that there is a book repository instance.
I suppose there are some classes of application where one might want to work on a remote repository but keep the application logic local. If that were the case, then one would want the book repository to be the interface which has the proxy and server. However, nothing in the architecture mentioned in the previous post precludes that use. If we had put the book repository into the interface for the use case rather than in its implementation, then we need to at least pretend there is a book repository on the local client even when everything is going to happen on the server.
Conclusion
An accidental benefit of Clean Architecture’s insistence on primitive or dumb-struct parameters to use-cases is that the parameters end up only reflecting the minimal amount of information that is specific to the current request. Any state that is common across requests is a part of the internal state of the use-case.
Because of this, code that is interacting with the use case only to know the little bit that makes them different from other people using the use case. This results in very simple interfaces to the use case and the a great deal of flexibility in implementation.