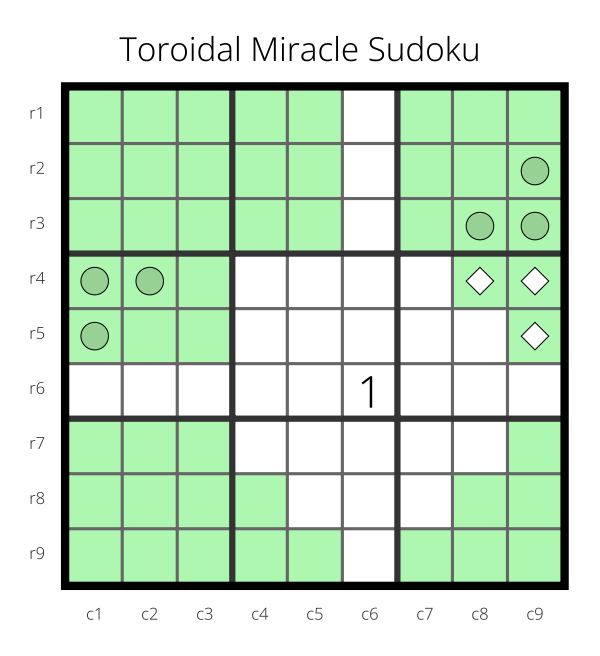
A few weeks ago, I was analyzing a Sudoku variant if the board were a flat torus instead of a square. I wrote a little paper about this analysis.
For that paper, I created the diagrams by taking screenshots of the f-puzzles Sudoku editor, pulling them into the GIMP image editor, cropping them all to the same dimensions, and pulling them into my document. I discovered a mistake that I had made throughout all of the images after I had already collected all of the screenshots. Rather than fixing the mistake by doing a new screenshot, I fixed things in the image editor instead of in the Sudoku editor.
It was painful.
So, I decided to make a way to declare a diagram and then render it so that it can be modified/corrected rather painlessly.
My initial cut at this was in CL-PDF. I realized, when I had finished, that I had only used a small subset of CL-PDF and that almost all of that functionality was available in Vecto (with a tiny bit of help from ZPB-TTF which Vecto uses already).
This was all the motivation that I needed to finally start on a project that I’ve been hoping to do for years now. I wrote a compatibility library that takes something very, very close to the subset of CL-PDF that I used in the diagram and renders it either using CL-PDF or Vecto so that I can have the output as either a vector image or a raster image.
I’d like to extend this sometime to also output to CL-SVG, but the way that fonts are handled in SVGs might make that impossible for most things one would want to do with text in a diagram.
You can find the library here: https://github.com/nklein/sudoku-diagrams