There were 35 candidates registered for the Minneapolis mayoral race this year. Minneapolis approved ranked-choice voting in 2006. I have great respect and deep sympathy for those who had to tabulate all of those votes. And, because there is no FEC-certified software for counting this type of vote, it was a huge human effort.
The Minnesota Secretary of State’s website has information about which candidates where eliminated in which of the 33 elimination rounds in the tabulation. I scraped the data from their Excel spreadsheet, added some Vecto, and put together some worm-trail charts. I couldn’t quite use Zach’s wormtrails library because I wanted to show how an eliminated candidates votes were redistributed (to other candidates who were lower-ranked choices or to the exhausted
bucket). Also, note: the tabulated data on the Minnesota Secretary of State’s website is insufficient to form an accurate proportioning in rounds when multiple candidates are eliminated. In those cases, I just assumed that all candidates whose votes were redistributed were redistributed in the same proportions to the candidates who gained votes because of the eliminations in that round.
About 450 lines of Lisp code later, I came up with images like the one below (click to see it at full-size):
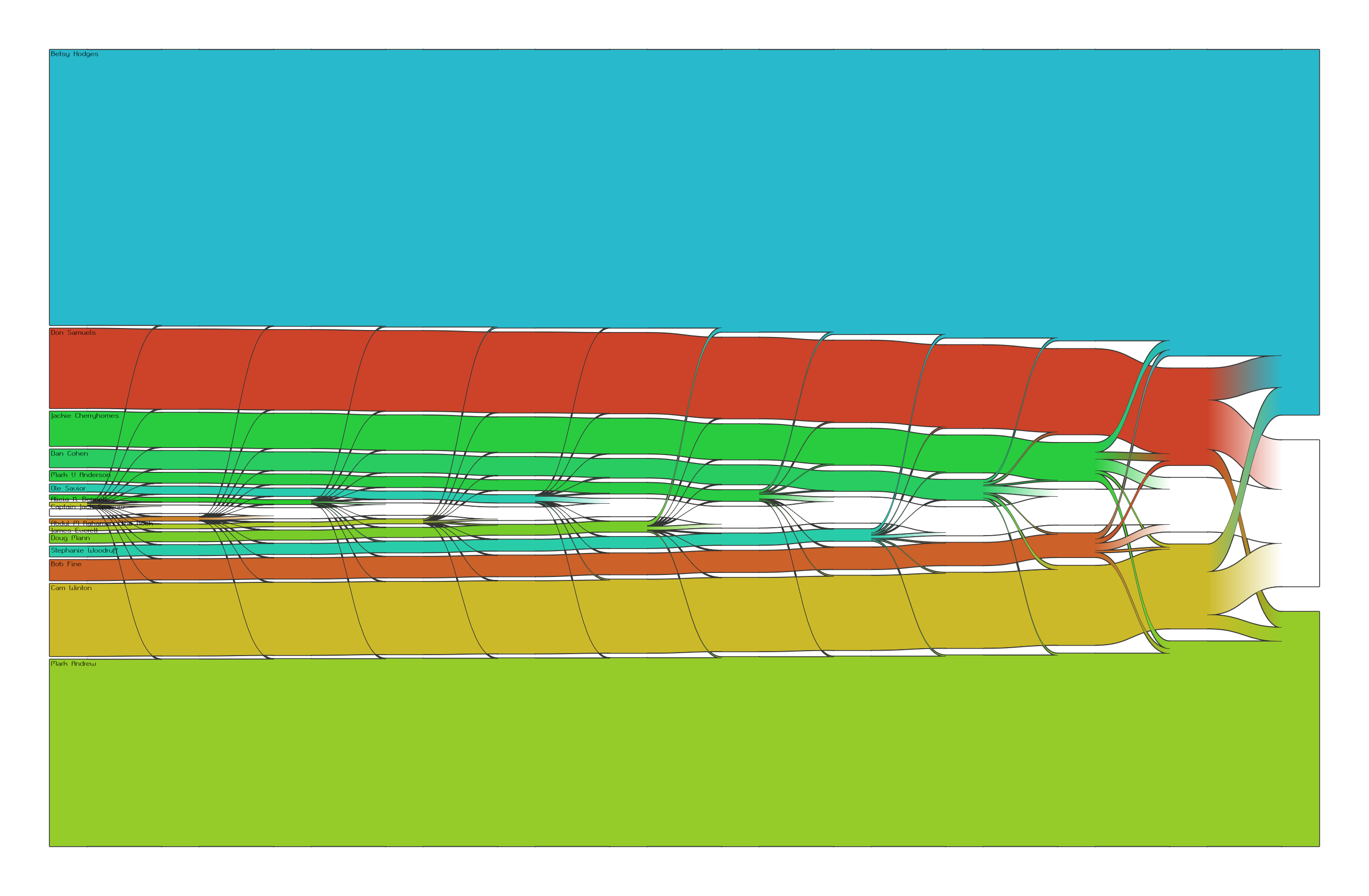
The white worm-trail through the center is the exhausted
pile. Unfortunately, the eliminated candidates in the first 25 or so rounds had so few votes that I’d have to render these images wall-sized for you to get any idea what proportion of their votes went where. In the final few rounds, you can see some detail even with a semi-reasonable file size. I suppose I should see if I can wrangle the data from the St. Paul race which only had six candidates (and thus fewer than six rounds of counting).
Here is the chart broken up into three sections to make it a bit more manageable:


Here is a link to all rounds in one big file. And, here is the source code: rcv.lisp.
{kind=link}
Note for Lisp folks: I don’t like the above code. I like short functions, but I also like using flet or labels to make functions that are still within lexical scope of a whole mess of variables. Anyone else come to a good resolution between those two things? Is bundling data in structs and classes really the right thing or a sea of global specials?