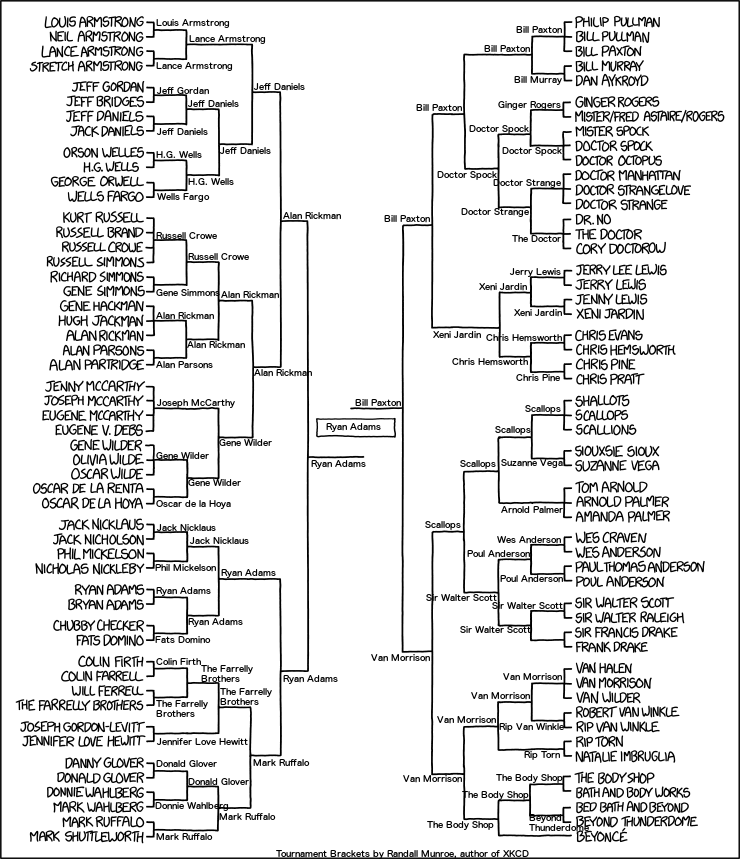
The web comic XKCD recently published the following tournament bracket featuring match-ups like ORSON WELLS vs. H.G. WELLS
and VAN HALEN vs. VAN MORRISON vs. VAN WILDER
.
So, who won? It seems probable to me that XKCD’s author Randall Munroe has in mind some way to decide these matches. If he published how the matches were to be decided, I missed it. However, based on some previous XKCD comics like Geohashing and Externalities, I think it’s a safe guess that it involves hashing.
So, how could we decide this? We could take the hash of each name and then in each match, the largest hash value wins. That, however, has the unfortunate side effect that the winner of the tournament would be the same regardless of the organization of the brackets.
I opted to decide the match between OSCAR DE LA RENTA
and OSCAR DE LA HOYA
by taking the SHA3-512 hash of the strings OSCAR DE LA RENTA vs. OSCAR DE LA HOYA
and OSCAR DE LA HOYA vs. OSCAR DE LA RENTA
. The winner is the one whose name appeared first in the string with the smallest hash value. For three and four person contests, I used all permutations of the players involved (separated by vs.
).
The winner? RYAN ADAMS beat out BILL PAXTON in the final.
The code for this project was a breeze thanks to #'ALEXANDRIA:MAP-PERMUTATIONS and my TRACK-BEST library. Here is a the meat of the whole thing which uses an evaluation function (here, it’s SHA3-512 of the vs.
separated player list) and a way to compare the evaluations (here, a simple #'ARRAY-LESSP) and runs through all of the players.
(track-best:track (first players)
(funcall eval-permutation players depth)))
(find-winner (players depth)
(track-best:with-track-best (:order-by-fn compare-permutations)
(alexandria:map-permutations (lambda (players)
(rank-one-match players depth))
players))))
...)
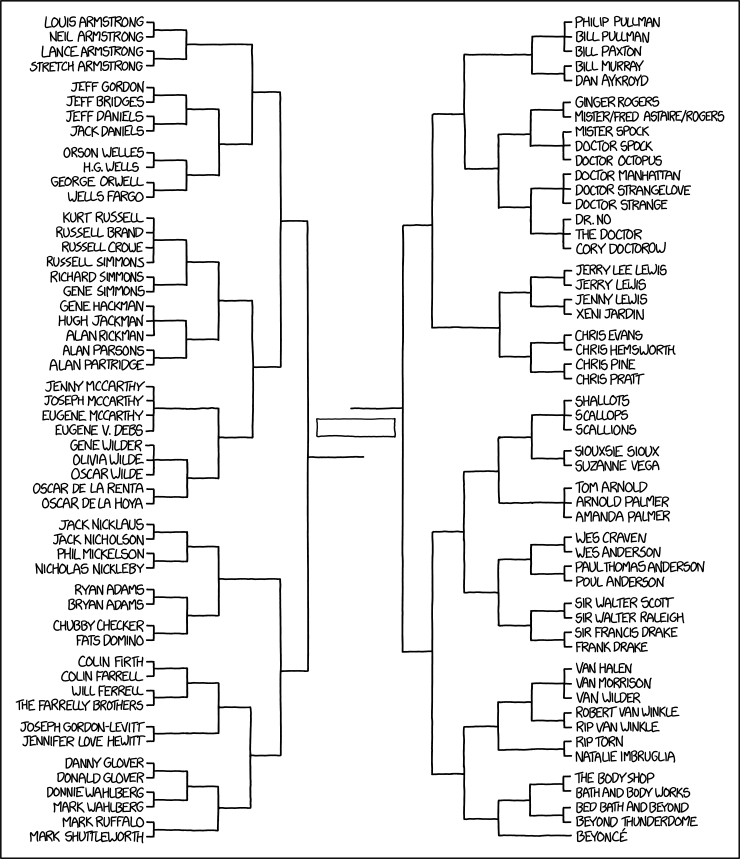
Here is the full source file for the tournament: tourney.lisp. Here is a text description of the whole tournament. And, here is a graphic with the outcomes of all of the matches.